Recently we start getting a few complains from our client related to connection on DataBase from IBM WAS. First action we have taken to take a look on log which we got from the client and discovered these following errors on application logs:
- Error 404: Database connection problem: IO Error: Got minus one from a read call DSRA0010E: SQL State = 08006, Error Code = 17,002
- java.sql.SQLException: The back-end resource is currently unavailable. Stuck connections have been detected.
With a quick search on google i have found PMR 34250 004 000 on IBM support sites, which is also effect IBM WAS 8.* version. As soon as we are using third party web portal engine (BackBase) it was travois to figure out the problem, so we decompiled some code to make sure that all the data source connection closing well. After some research i have asked data base statistics and data source configurations from support team of the production. And i was surprised with the data base statistics that all connection on DataBase was full and IBM application server could not get any new connection to complete request.
On Oracle DataBase, maximum connection was set to 6000 and we have more than 32 application server with Maximum Connection 200. It was a serious mistake, formula for configuring connection pool of IBM cluster is as follows:
Maximum Number of Connection in Node * Quantity of Nodes < Max Connection set to Database
In our case, configuration should be
200 * 32 < 6000
We send a request to increase the DataBase connection in Oracle to 10 000. But what to do with the stuck connection? I have checked the IBM WAS advanced connection pool properties and noticed that, stuck connection properties are configured at all.

Lets check, what the Stuck connection is?
A stuck connection is an active connection that is not responding or returning to the connection pool. Stuck connections are controlled by three properties, Stuck time , Stuck threshold and Stuck timer interval.
Stuck time
- Time for a single active connection to be in use to the backend resource before it is considered to be stuck.
- For example, stuck time is 120 seconds and if the connection is waiting on database for more than 120 seconds then the connection would be marked as Stuck
Stuck threshold
- The stuck threshold is the number of connections that need to be considered stuck for the pool to be in stuck mode
- For example, if the threshold is 10 and after 10 connections are considered stuck , whole pool for that datasource is considered Stuck
Stuck Timer Interval
- Interval at which , how often the connection pool checks for stuck connections
With the above information i have configured the following Stuck connections properties:
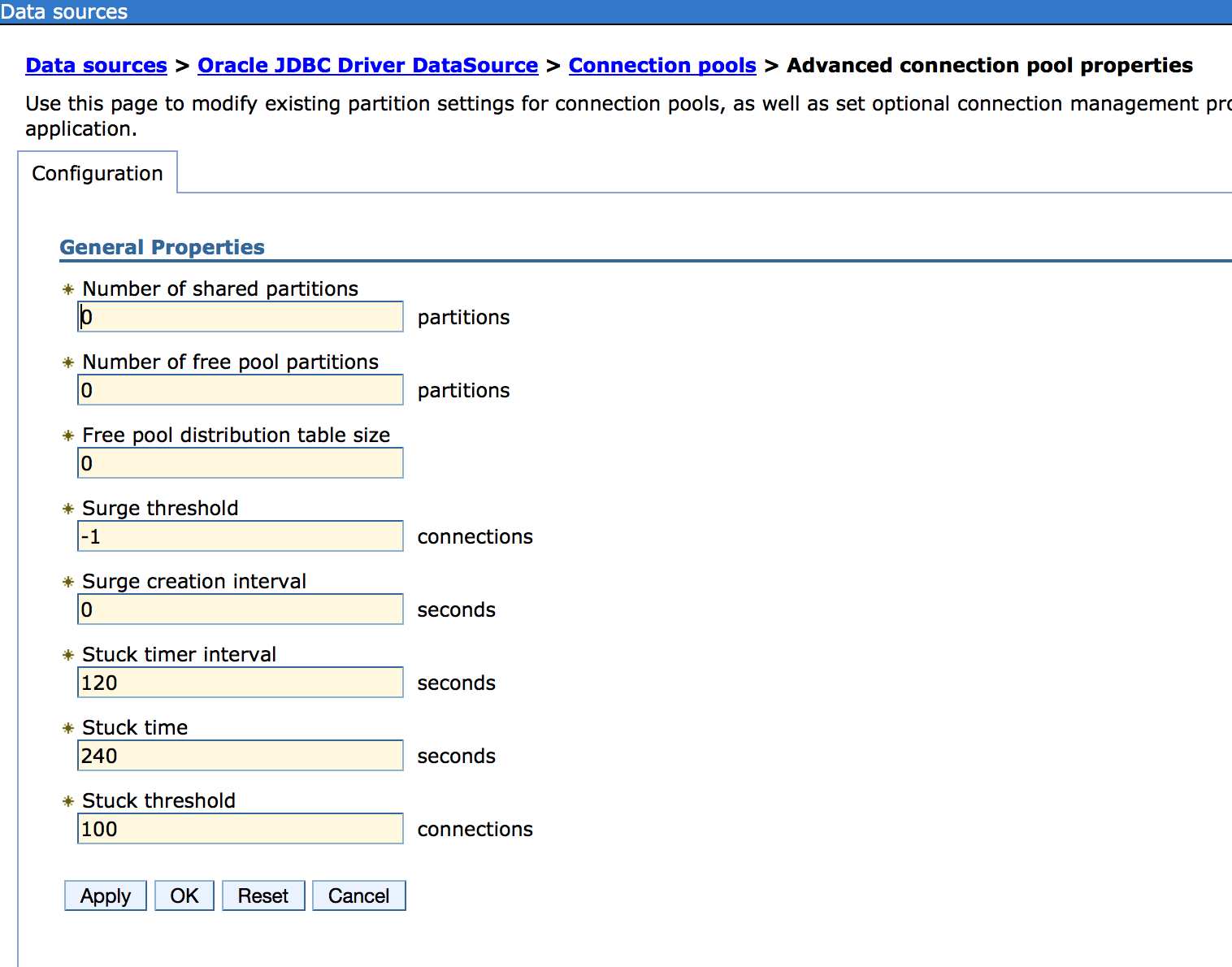
With the above configuration, when the connection pool will be declared as stuck?
Stuck timer interval : 120 secs
Stuck time : 240 secs
Stuck threshold : 100 connections (maximum connection 200)
What happens when pool is declared stuck ?
- A resource exception is given to all new connection requests until the pool is unstuck.
- An application can explicitly catch this exception and continue processing.
- If the number of stuck connections drops below the stuck threshold, the pool will detect this during its periodic checks and enable the pool to begin servicing requests again
Also it is very useful to check inactive connection periodically in Oracle Database, if some connection is hang and inactive you can drop this connection manually.
Here is a pseduo query to find inactive connection in DB
SELECT s.username, s.status, S.sid || ',' || S.serial# p_sid_serial from v$session s, v$sort_usage T, dba_tablespaces TBS where (s.last_call_et / 60) > 1440 AND T.tablespace = TBS.tablespace_name and T.tablespace = 'TEMP';
Hope the above information will help somebody to quick fix in IBM WAS.
Comments