One of my few blog posts i have mentioned how to use and the use cases of using Oracle DataBase changed notification. When you have to need context search or count facts over your datas, you certainly need any modern Lucene based search engine. Elastic search is one of that search engine that can provide those above functionalities. However, from the previous versions of ES, elastic search river is deprecated to ingesting data to ES. Here you can get the whole history about deprecating river in ES. Any way, for now we have two option to ingest or import data from any sources to ES:
1) Implements or modify your DAO services, that can update data in ES and DataBase same time.
2) Polling, implements such a job, which will polling data in some period of time to update data in ES.
First approach is the very best option to implements, however if you have any legacy DAO services or 3rd party application that you couldn't make any changes is not for you. Polling to data base frequently with huge data can hard the performance of the DataBase.
In this blog post i am going to describe an alternative way to ingest data from data base to ES. One of the Prerequisites is that, you have Oracle Database with version higher than 9.0. Also i added the whole code base in github.com to explorer the capability.
Here is the data flow from Oracle to ES:
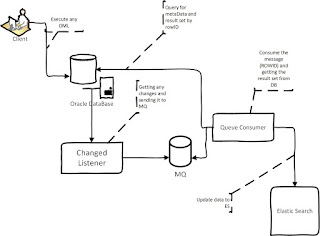 Data Flow is very simple:
Data Flow is very simple:
1) Registered listener getting changes (RowID, ObjectId[~tableID]) for every commit in DB.
2) Listener send the changes (RowId, ObjectId) in xml to any MQ, we are using Apache Apollo.
3) Consumer of the queue collects the messages and query to the DataBase for Table meta data and result set by rowId.
4) Consumer build the result set in JSON format and index the result set in ES.
Git hub repository contains the three module to implements the data flow.
[qrcn] - collect notification from Oracle and send the notifications to any existing queue [apollo].
[es] - consumer, collects the message from the queue and index in Elastic search
[es-dto] - common dto
You can change your Query notification on QRCN module (file connection.properties).
Any way, at these moment project contains the following prerequisites:
1) racle JDBC 11g driver needs to compile the project.
2) apache zookeeper
3) apache Apollo
4) elastic search
Any way, you can always make any changes by your requirements. Happy weekend.
1) Implements or modify your DAO services, that can update data in ES and DataBase same time.
2) Polling, implements such a job, which will polling data in some period of time to update data in ES.
First approach is the very best option to implements, however if you have any legacy DAO services or 3rd party application that you couldn't make any changes is not for you. Polling to data base frequently with huge data can hard the performance of the DataBase.
In this blog post i am going to describe an alternative way to ingest data from data base to ES. One of the Prerequisites is that, you have Oracle Database with version higher than 9.0. Also i added the whole code base in github.com to explorer the capability.
Here is the data flow from Oracle to ES:

1) Registered listener getting changes (RowID, ObjectId[~tableID]) for every commit in DB.
2) Listener send the changes (RowId, ObjectId) in xml to any MQ, we are using Apache Apollo.
3) Consumer of the queue collects the messages and query to the DataBase for Table meta data and result set by rowId.
4) Consumer build the result set in JSON format and index the result set in ES.
Git hub repository contains the three module to implements the data flow.
[qrcn] - collect notification from Oracle and send the notifications to any existing queue [apollo].
[es] - consumer, collects the message from the queue and index in Elastic search
[es-dto] - common dto
You can change your Query notification on QRCN module (file connection.properties).
querystring=select * from temp t where t.a = 'a1';select * from ATM_STATEAlso i add zookeeper to QRCN module to be fault tolerate.
Any way, at these moment project contains the following prerequisites:
1) racle JDBC 11g driver needs to compile the project.
2) apache zookeeper
3) apache Apollo
4) elastic search
Any way, you can always make any changes by your requirements. Happy weekend.
Comments