Inspired by the following post WebLogic Load Balancing for Oracle ADF Applications i have decided to make some agile test for GWT applications.
First we will develop a simple hello world GWT application and configure load balancing cluster. Sample GWT application will be deployed on WebLogic cluster, Load Balancing domain or proxy domain will distribute user requests between cluster members.
1) Develop sample GWT application
It's a hello world web application with one text field and button on a web page. I use maven to develop the application. We can choose any web application to deploy on web logic cluster, any way our aim is to configure web logic cluster and we will go though all over the steps next.
2) Configure cluster domain
It's very easy to setup and configure cluster on web logic. Just start Configuration wizard and select customize installation.
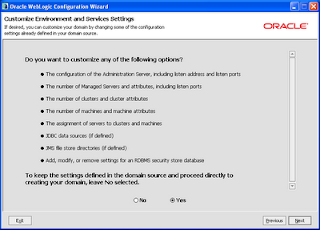
Change port number of the Admin server, in my case it is 7002
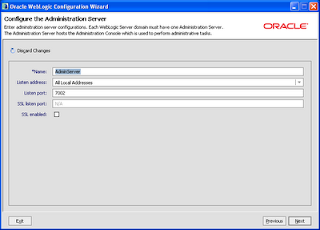
On Configure Managed server page add two new managed server and change the port to 7003 and 7004.
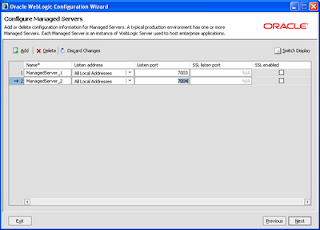
Configure cluster by default and we will change the multicast to unicast.
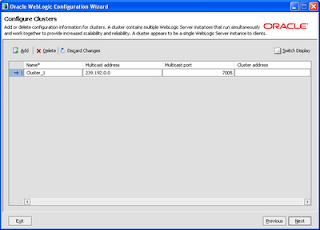
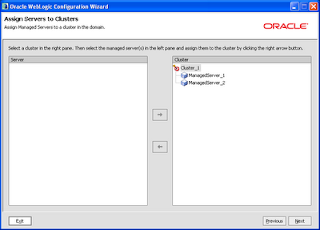
On the next page assign all the managed servers to the cluster.
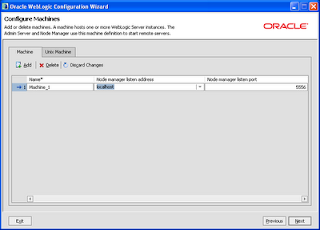
On the configure machine page add one physical machine and address the listen address to localhost as follows:
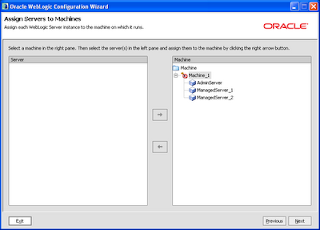
On next page apply cluster with manged serves to physical machine:
And finally provide domain name and the location of the domain. In my case i have provide the domain name as cluster_domain.
At this moment cluster is installed and ready to use. Start the cluster domain from program menu, and open the console by following url:
http://localhost:7002/console
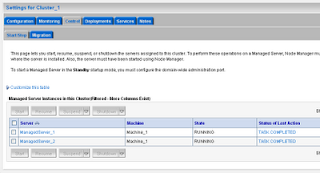
Start node manager from the start menu to manage managed servers, go to the console home page->cluster->control and select all the managed servers and click to start. After a few moments states of the servers should be running mode.
Now, it's time to deploy our GWT web application on cluster. Deploy the web application on cluster by web inteface as follows:
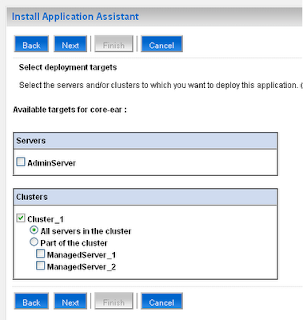
3) Set Up the HttpClusterServlet:
Here we will describe how to develop and configure proxy plugin for load balancing. We will use a web logic domain as a proxy plugin and configure HttpClusterServlet on it. To use http cluster servlet, configure it as a default web application on proxy domain. The default web application will only contain a web.xml and weblogic.xml file on WEB-INF directory and nothing more. See the link to more about HttpClusterServlet.
I have used sample web.xml and weblogic.xml available in documentation, just changed WebLogicCluster parameter value to:
localhost:7003|localhost:7004
and build an web application with war archive, name the archive as loadBalancer.war
At this moment we will create another weblogic domain with standard configuration and name the domain as proxy_domain. Deploy the loadBalancer.war on the proxy domain as follows:
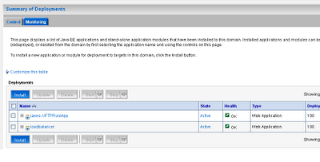
4) Test the configuration.
For now we have configured everything to test our web application running on cluster. Address you web applications home page on any browser, in my case it is as follows:
http://localhost:7001/app-name/context-root/HelloGwt.html
One of Managed Servers from Cluster environment will response. Go to the following location to check the output log from the server
\user_projects\domains\cluster_domain\servers\ManagedServer_1\logs\ManagedServer_1.out
In my case server 1 response in this time, if i have opened second session, by pointing to the same 7001 port and it was handled by seconed Managed Server and so on. It was because cluster server was configured with round-robin algorithm.
The above configuration will consider for any web application not just fro GWT application. There are a lot of configuration left behind on httpServlet plugins.
For more information please see following resource:
Load Balancing with a Proxy Plug-in
First we will develop a simple hello world GWT application and configure load balancing cluster. Sample GWT application will be deployed on WebLogic cluster, Load Balancing domain or proxy domain will distribute user requests between cluster members.
1) Develop sample GWT application
It's a hello world web application with one text field and button on a web page. I use maven to develop the application. We can choose any web application to deploy on web logic cluster, any way our aim is to configure web logic cluster and we will go though all over the steps next.
2) Configure cluster domain
It's very easy to setup and configure cluster on web logic. Just start Configuration wizard and select customize installation.

Change port number of the Admin server, in my case it is 7002

On Configure Managed server page add two new managed server and change the port to 7003 and 7004.

Configure cluster by default and we will change the multicast to unicast.

On the next page assign all the managed servers to the cluster.

On the configure machine page add one physical machine and address the listen address to localhost as follows:

On next page apply cluster with manged serves to physical machine:

And finally provide domain name and the location of the domain. In my case i have provide the domain name as cluster_domain.
At this moment cluster is installed and ready to use. Start the cluster domain from program menu, and open the console by following url:
http://localhost:7002/console
Start node manager from the start menu to manage managed servers, go to the console home page->cluster->control and select all the managed servers and click to start. After a few moments states of the servers should be running mode.

Now, it's time to deploy our GWT web application on cluster. Deploy the web application on cluster by web inteface as follows:

3) Set Up the HttpClusterServlet:
Here we will describe how to develop and configure proxy plugin for load balancing. We will use a web logic domain as a proxy plugin and configure HttpClusterServlet on it. To use http cluster servlet, configure it as a default web application on proxy domain. The default web application will only contain a web.xml and weblogic.xml file on WEB-INF directory and nothing more. See the link to more about HttpClusterServlet.
I have used sample web.xml and weblogic.xml available in documentation, just changed WebLogicCluster parameter value to:
localhost:7003|localhost:7004
and build an web application with war archive, name the archive as loadBalancer.war
At this moment we will create another weblogic domain with standard configuration and name the domain as proxy_domain. Deploy the loadBalancer.war on the proxy domain as follows:

4) Test the configuration.
For now we have configured everything to test our web application running on cluster. Address you web applications home page on any browser, in my case it is as follows:
http://localhost:7001/app-name/context-root/HelloGwt.html
One of Managed Servers from Cluster environment will response. Go to the following location to check the output log from the server
In my case server 1 response in this time, if i have opened second session, by pointing to the same 7001 port and it was handled by seconed Managed Server and so on. It was because cluster server was configured with round-robin algorithm.
The above configuration will consider for any web application not just fro GWT application. There are a lot of configuration left behind on httpServlet plugins.
For more information please see following resource:
Load Balancing with a Proxy Plug-in
Comments